

Introduction
Sim03, a chess engine similarity measuring tool, was developed in the period 2010-12 by Don Dailey, one of the programmers of the chess engine Komodo series. A chess engine was presented with 8238 chess positions and asked for its top move choice. A pair of different chess engines could then be compared for similarity by matching up and counting the number of positions for which each engine chose the same move.
It's successor Simex is thus a similarity by outcome tool. Chess engines 'think' using a combination of evaluation (the smart part) and search, which tends to be more algorithmic. The increasing ability of engines to search very deep over the last few years has decreased the value of the Sim03 tool, as, arguably, deep searchers will be more inclined to choose similar moves, with less ability for Simex to discriminate between them.
Ed Schröder, the programmer of the Rebel series of chess engines, recently devised a technique to use Simex to consider only the evaluation part of a chess engine, by limiting the engine search depth to one move ahead only, effectively disabling its search function. An added bonus was that the 8238 chess positions could now be evaluated by any chess engine using UCI, Universal Chess Interface protocols, in a matter of minutes or less.
Around one hundred and fifty chess engines were available for testing, some were unsuitable, but one hundred and thrity five remained, and after testing all these engines and comparing all engine pairs, we were able to produce a 135x135 chess engine similarity or correlation matrix containing around nine thousand correlation values, with each engine-pair correlation value expressed as a percentage figure.
Correlation Similarity meaning.
The upper bound of similarity/correlation is 100%, we would expect the evaluation of two identical engines to agree with each others move choice 100% of the time. We find a lower bound in the data of around 30 to 40% for the chess positions used, assumedly unconnected engines appear to generate the same move for a position around one time in three, suggesting the test suite has, on average, around three 'sensible' candidate moves that a 'sensible' evaluation function would choose between.
All tested engines in this report are of the alpha-beta type, so our proposed baseline is an alpha-beta baseline. When we test as many neural net engines as possible for our next report, we may well discover a different baseline figure for move variance, since neural net engines anecdotally evaluate positions differently to alpha-beta handcrafted evaluation functions.
________________________________________________________________________________________________
In case you are not familiar what this is about we recommand you to read a sort of introduction course first followed by the SIMEX documentation.
Without going through the past and the numerous clones and derivatives that came from Crafty, Fruit 2.1, Rybka 1.0, Rybka 3 we want to present the current situation of 2019. And the current state looks good except for a couple of unexpected remarkable exceptions.
Table one
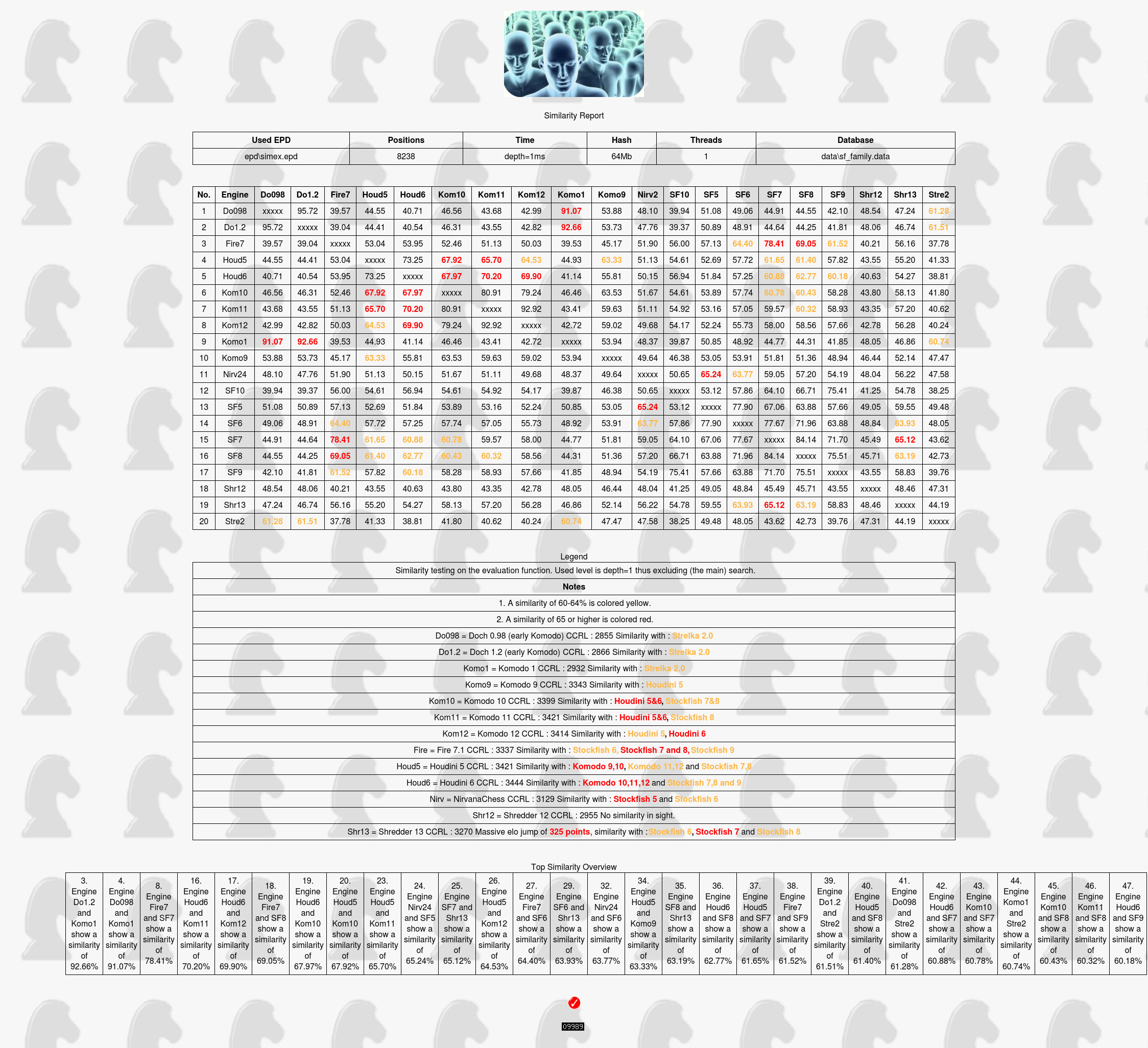
Click to enlarge
Notes
1. Doch is the precursor of Komodo.
2. Strelka is hacked Rybka 1.0
3. After the open sources of Crafty, Fruit, Strelka, Ippolit and friends the new target to borrow from is Stockfish.
Engine | CCRL | 60-64% | > 65% |
Doch 0.98 | 2855 | Strelka 2.0 | |
Doch 1.2 | 2866 | Strelka 2.0 | |
Komodo 1 | 2932 | Strelka 2.0 | |
Komodo 9 | 3343 | Houdini 5 | |
Komodo 10 | 3393 | Stockfish 7, Stockfish 8 | Houdini 5, Houdini 6 |
Komodo 11 | 3421 | Stockfish 7 | Houdini 5, Houdini 6 |
Komodo 12 | 3414 | Houdini 5 | Houdini 6 |
Fire 7.1 | 3337 | Stockfish 6 and Stockfish 9 | Stockfish 7 and Stockfish 9 |
Houdini 5 | 3421 | Komodo 11,12 and Stockfish 7,8 | Komodo 9 and 10 |
Houdini 6 | 3444 | Stockfish 7,8 and 9 | Komodo 10,11 and 12 |
NirvanaChess | 3129 | Stockfish 6 | Stockfish 5 |
Shredder 12 | 2955 | No similarity in sight. | |
Shredder 13 | 3270 | Massive elo jump of 325 points, similarity with Stockfish 6 and Stockfish 8 | Stockfish 7 |
_________________________________________________________________________________________________
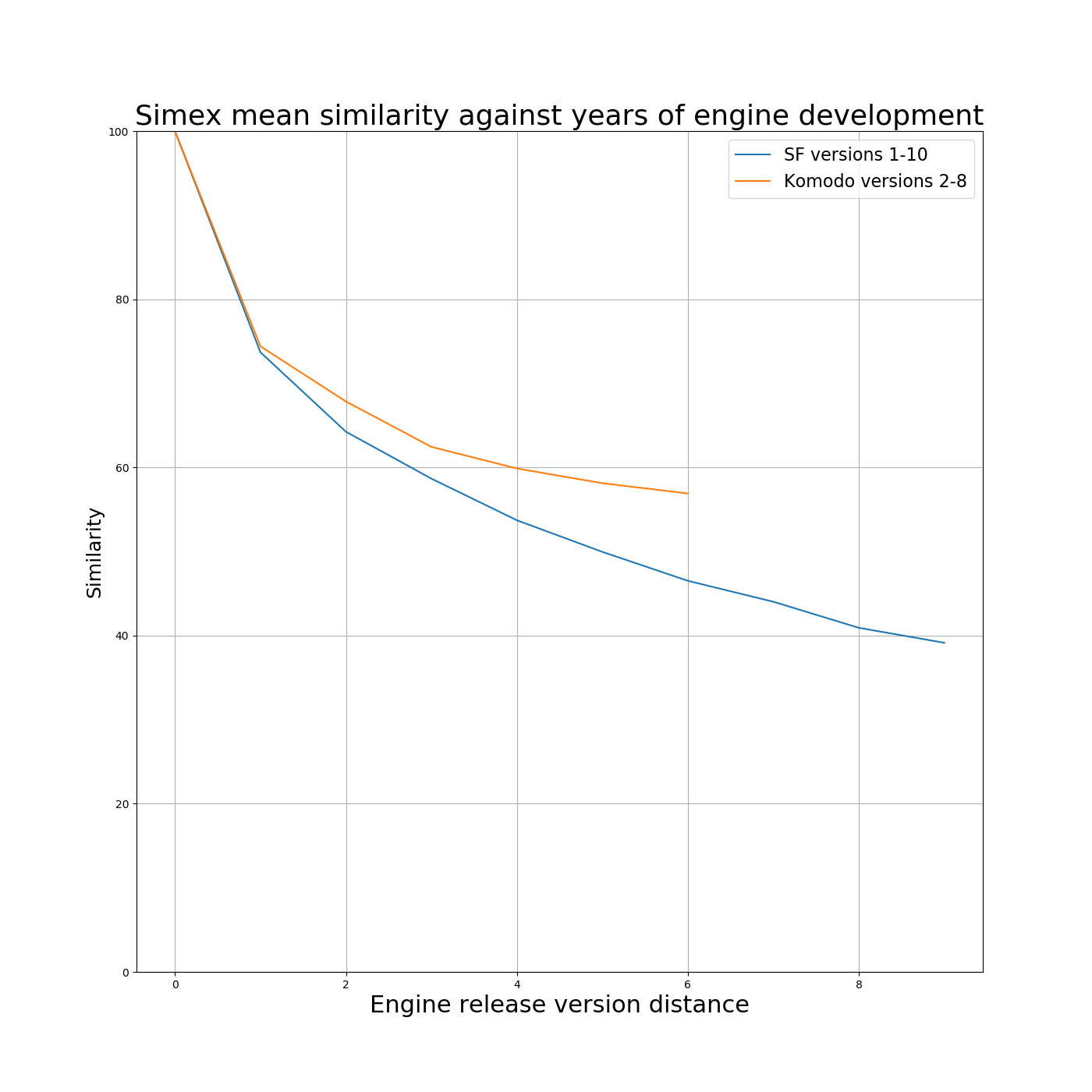
On Stockfish from the HTML data we can extract the following information
Stockfish development years | Sim Score |
1 | 73.69 |
2 | 64.24 |
3 | 58.66 |
4 | 53.71 |
5 | 49.95 |
6 | 46.51 |
7 | 44.02 |
8 | 40.92 |
9 | 39.14 |
Komodo development years | Sim Score |
1 | 74.40 |
2 | 67.84 |
3 | 62.44 |
4 | 59.87 |
5 | 58.12 |
6 | 56.90 |
The original Simex was created with a ‘line in the sand’ drawn as derivative/clone marker set at 60%. This marker level was really quite arbitrary, agreed after 'discussion', as Ed Schröder has posted , aka it's a political line. “...... there was a big discussion at the time, some wanted the marker on 55%, others on 65%, but the majority was in favor for 60%, a close general consensus".
It ought to be possible with all the data we have, to try and rationalise the 'line in the sand' or at least give it some meaning. So, to this end:
By comparing SF10 with SF9 and so on, one development year apart, two development years apart and so on and so on back to SF1. Then averaging the similarity scores for one year back, two years back and so on, we have a metric for what the various similarity scores mean in terms of years of SF development. NB I’m assuming Stockfish releases a new version every year or so. Same again for Komodo versions 2 to 8.
From the table, we can see that a sim score of 50% between two engines, would represent about five years of continuous development for Stockfish, from, say SF5 to SF10.
65% would be about 1.9 years separation.
60% would be about 2.5 years separation.
55% would be about 3.5 years separation.
50% would be about 5.0 years separation.
Of course, all Stockfishes are derivatives of earlier Stockfishes.
As programs such as Hiarcs14, Arasan, ProDeo etc. show us, the similarity score for independent programs (well, I assume, and the data confirms) is down in the 35 to 40% range.
Many, many programs that Ed has tested score
Click to enlarge
35-40% across the board against everything they've been tested against. Others don't.
Well, now you have a kind-of comparison metric. If an engine gets a Simex score of 65% against some other engine, that's comparable to the kind of score Stockfish 8 and Stockfish 10, or SF6 and SF4 and so on, would get.
Analysis by Chris Whittington
____________________________________________________________________________________________
More on the yellow 60% and red 65% markers
A good example would be Fruit 2.1 and how several programmers tried to improve the source code obeying the GPL.
The most known legal Fruit derivatives were the TOGA series and Fruit 2.2 and Fruit 2.3, we tested them to measure how the similarily developed.
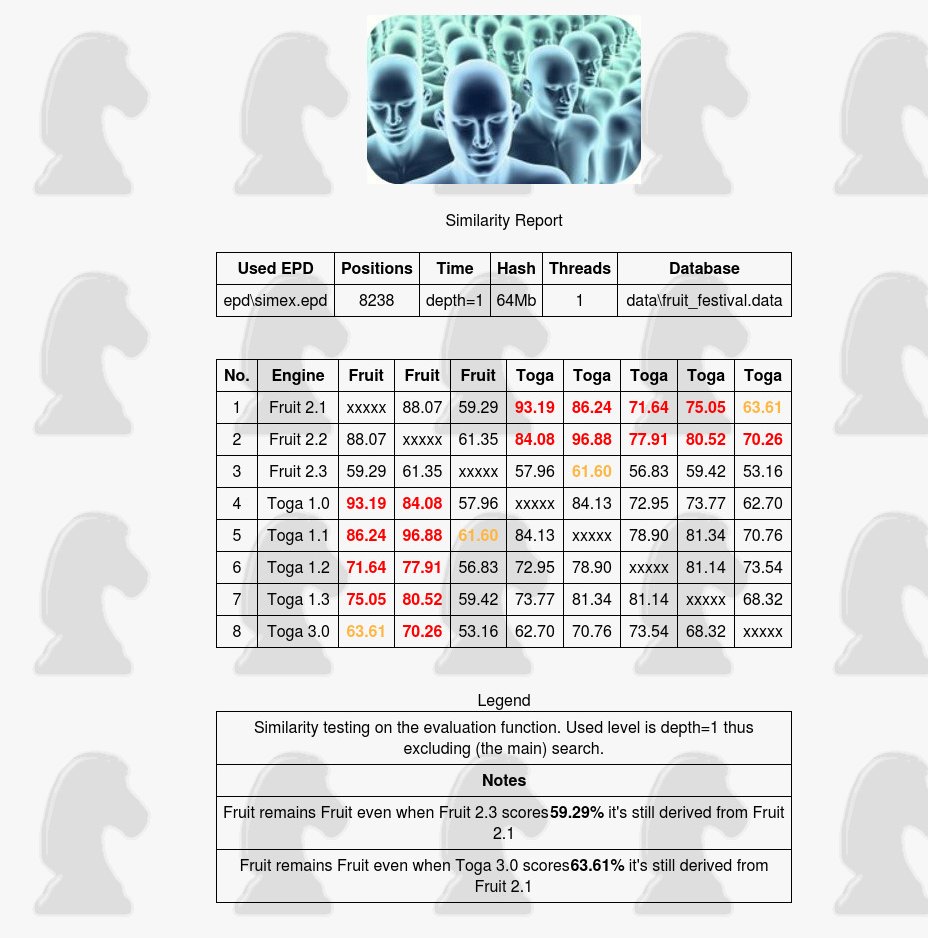
Fruit 2.3 | Toga 3.0 | |
Fruit 2.1 | 59.29% | 63.61% |
From the page you can see how the similarity drops version by version, Toga 3.0 at 63% and Fruit 2.3 even below the yellow 60% marker.
A similar overview can be made from any engine derived from Stockfish or Fruit or other open source, whether openly or not, the longer the development the more the similarity tends to drop. Fruit 2.3 and Toga 3.0 (an official derivative of Fruit) remain what they are, derivatives of the earlier Fruit engine.
Bottom line:
The 60% yellow and 65% red markers work both ways
backwards and forwards.
_______________________________________________________________________________________________
Similarity in graphs

Networkx graph of 69 engines (of the 135) we tested. More on NetworkX graphs below.
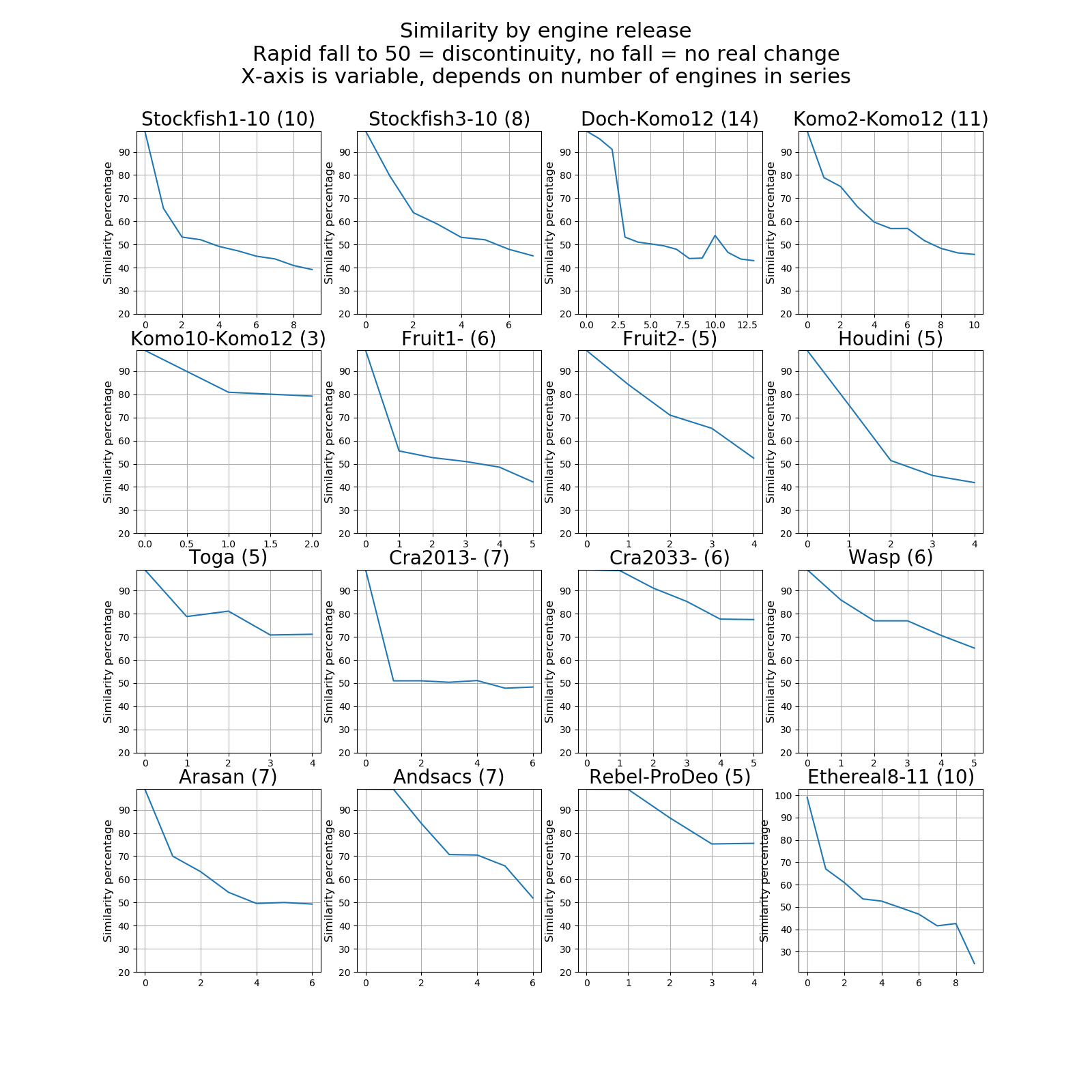
Graphs of Release Version Similarity against Release Version Number.
Here we have plotted the similarity of each consecutive release of an engine against the initial engine in the series. Note that some graphs are compressed along the x-axis, because the lengths of engine release series differ according to available data.
Observations:
1. Where the graph remains flat, there is little or no difference between one version and the next.
2. If the graph rapidly falls to 50, we assume there is a discontinuity in the development, and we then plot another graph for that engine, starting at the discontinuity point. Examples being Komodo2 and Stockfish3.
3. There is a glitch in the Komodo graph at Komodo 9. This might imply a development reversion.
4. The Rebel / ProDeo graph is based on Gideon Pro (1993), Rebel 6 (1996), Rebel Century (2000-2003), ProDeo 1.85 (2013) and ProDeo 2.2 (2017) the last ProDeo. As one can see from the graph not much happened to the evaluation function after Rebel Century (2000-2003).
________________________________________________________________________________________________
How much is enough ?
Since the old SIM03 had an unchangeable fixed set and number of 8238 positions we wondered if a set of 100,000 random positions would change the numbers as after all it was never researched. The pattern remains intact, the similarity numbers even increased somewhat. The set in parts of 10,000 can be downloaded here.
Table two
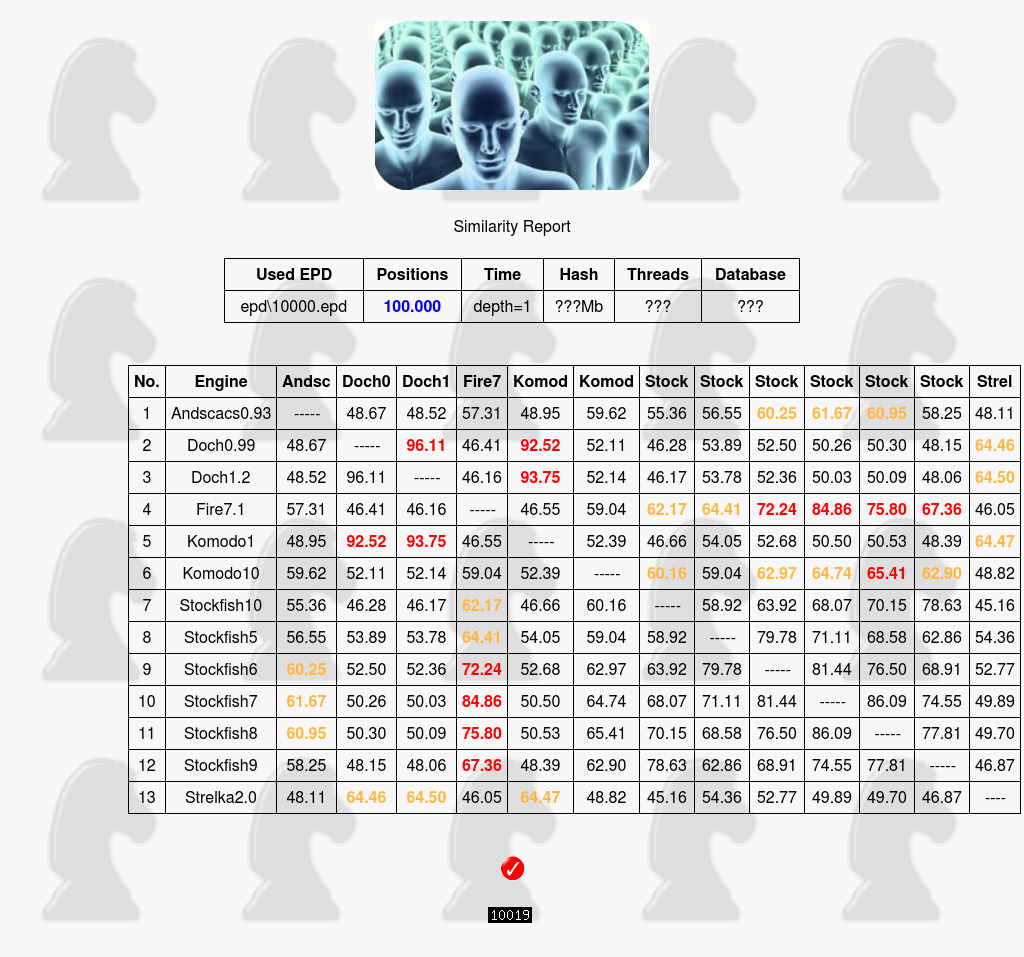
Click to enlarge

{kind=link}
Click to enlarge
_________________________________________________________________________________________________
Similarity versus ELO
and the relationship between them
From table one above:
1. The most striking example we found is when we compare Shredder 12 with Shredder 13. While Shredder 12 has no similarity with any other engine with Shredder 13 and the massive elo jump of 325 points the similarity with Stockfish jumps with it, with SF7 even over 65%.
2. Second comes Houdini 5. Houdini 4 is CCRL rated 3240 makes with Houdini 5 a giant jump of 180 elo points. At the same time we see the similarity with Stockfish 7 increase from 40.14% to 61.65%
3. Komodo is another story. Komodo 8 is CCRL rated 3235 and no similarity in sight. Komodo 9 jumps to 3343 an 118 elo increase suddenly showing similarity with Houdini 5. With Komodo 10 (+50 elo) also similarity with Stockfish 7 and 8.
4. While Crafty doesn't quite cross the arbitrary yellow marker it's another example of the relationship between increasing Elo and increasing similarity. We tested five Crafty's (those we have) and with the step Elo jump of 220 points from version 22.0 to 23.3, the similarity with Fruit and Strelka also jumps. As one also can see there is no relationship with the evaluation of Stockfish.
CCRL | Fruit 2.1 | Rybka 1.0 | Strelka 2.0 | |
Crafty 20.13 | 2519 | 43.51 | 42.24 | 43.98 |
Crafty 21.5 | 2542 | |||
Crafty 22.0 | 2537 | |||
Crafty 23.3 | 2758 | 57.00 | 57.19 | 59.21 |
It's likely more of such patterns can be found in the engines we tested but those 4 examples should be enough to conclude that it makes a lot of sense to take from stronger evaluation functions.
Lumping these 4 engines togerther we get:
Emgine | From | To | Increase | Similarity with Engine(s) |
Shredder 12 to 13 | 45.49 | 65.12 | 19.7% | Stockfish 6, Stockfish 7 and Stockfish 8 |
Houdini 4 to 5 | 40.14 | 61.65 | 21.5% | Stockfish 7 and Stockfish 8 |
Komodo 8 to 9 | 48.54 | 63.33 | 14.8% | Houdini 5 |
Komodo 9 to 10 | 51.81 | 60.78 | 9% | Stockfish 7 and Stockfish 8 |
Crafty 22.0 to 23.3 | 43.51 | 57.00 | 14.5% | Fruit 2.1 |
Crafty 22.0 to 23.3 | 43.98 | 59.21 | 16.7% | Strelka 2.0 |
_______________________________________________________________________________________________
Incompatible Engines
We tested a lot of engines which results we couldn't use in our data for various reasons such as for not supporting the UCI depth, hiding the mainlines for the first x iterations or in a few cases a very strange low similarity compared to their precursors or successors. The list:
Engine | UCI depth support | Hide mainlines | Other |
Booot 6 | Probably | Yes | |
Defenchess_2.1 | No | No | |
Fizbo 2 | No | Yes | |
Gaviota 0.85 | No | No | |
Jonny 4.00 | No | Probably | |
Laser 1.5, 1.6, 1.7 | No | No | |
Naum 4.6 | No | No | |
Pedone 1.8 | Yes | No | Strange low similarity compared to 1.6 and 1.9 |
Protector 1.9 | No | No | |
Rybka 1,2,3 and 4 | Obfuscated depths, not obeying number of threads, a number of bugs in the time control. | ||
rofChade | No | Yes | |
RubiChess 1.4 | Yes | No | Makes MEA to abort due to a syntax error in case of promotions. There will be a work around in the next SIMEX release. |
Senpai 2 | Yes | No | Strange low similarity compared to Senpai 1 |
Vajolet 2.7 | Yes | Yes | Hides depth 1 and crashes also. |
Nevertheless we publish the similarity results with the remark the numbers
of these engines are unreliable.
________________________________________________________________________________________________
Similarity videos
Engine (nodes) and similarities between them (edges or links) are laid out within a 2-dimensional space using a Force-directed graph drawing algorithm. In this case the Fruchterman-Reingold variant. The algorithm attempts to keep connected nodes together whilst minimising the number of edge cross-overs. Nodes that are not connected tend to be further apart. The result has the effect of collecting engines into family groups, based on similarities (which we measure using the Simex tool).
The Simex tool measures how often an engine-pair choose an identical chess move in the same chess position. A 50% score means on average the engine-pair are selecting the same move for one move out of every two. Each engine is represented by a labelled node and Elo, and 'links' between "engines by a dark connecting line, the line thickness being a measure of similarity. Thicker line = more similarity. Sim trigger is the similarity that 'triggers' whether a link is drawn.
Watch the below Youtube videos and how evaluation similarity slowly comes to life.
Hints:
- Best viewed in full screen mode.
- The first video is a random example taken from the 135 engines tested to show that most of the 135 show no similarity with other engines. Thereafter the focus is on engines that do show similarity.
- Or start with video 10 (Most Engines) to get familar with the graphics first.
Stockfish Wasp Arasan
Example of a number of independent engines taken from the 135 engines tested.
Shredder and Fire borrowing
evaluation from Stockfish.
The strange Houdini Komodo
connection one more time in more detail.
Most Engines
Screen gets cluttered
Nirvana Ethereal Cheng Crafty Wasp Fruit Rybka
Stockfish Schooner Xiphos Pedone Hannibal Andsacs
Note the extreme high similarity of 83.57% between Schooner and Xiphos 0.3
Early Komodo's similarity with Fruit, Rybka, Strelka. Later Komodo's with Houdini and Stockfish.
Stockfish Nirvana Fire
Stockfish evaluation similarities.
Way Too Many Engines not enough screen.
Some chess engines are more equal than others.
The Fruit and Robbolito family, the 2010-2014 period before Stockfish became into the picture as next engine to borrow from.
Stockfish Houdini Komodo
and the strange connection between the last two.
Blast from the past and the
derivatives that came from Ippolit and Robbolito.
Stockfish Komodo Shredder Fire
Shredder surprise, similarity with Stockfish.
Rybka Fruit early Komodo Robbolito Crafty early Houdini Critter
Rybka Fruit early Komodo Robbolito Crafty early Houdini Critter
Rybka Fruit early Komodo Strelka Crafty early Houdini
Artwork by Chris Whittington
______________________________________________________________________________________________
Other Engines
Other than the well known engines which we have shown results for, the Simex tool also discovered a number of unexpectedly high levels of similarity in several other engines, these are:
Engine | CCRL | Similarity | With |
Fire 7.1 | 3336 | 78.41% | Stockfish 7 |
Nirvanachess 2.1 | 3101 | 67.31% | Stockfish 5 |
Equinox 3.3 | 3161 | 66.89% | Robbolito |
Gull 2 | 3098 | 64.62% | Robbolito |